Global Bag-of-Features Models in Random Fields for Joint Categorization and Segmentation
Our work [1] introduces a new class of higher order potentials for joint categorization and segmentation, which encode the cost of assigning a label to large regions in the image. Such potentials are defined as the output of a classifier applied to the histogram of all the features in an image that get assigned the same label. These top-down potentials can seamlessly be integrated with traditionally used bottom-up potentials, hence providing a natural unification of global and local interactions. The parameters for these potentials can be treated as parameters of the Conditional Random Field (CRF) and hence be jointly learnt along with other parameters of the CRF. For this purpose, we proposed a novel framework for learning classifiers that are useful for categorization as well as for multi-class segmentation. Experiments on the Graz and CAMVID datasets showed that our framework improves the performance of multi-class segmentation algorithms.
Learning Top-down Sparse Representation for Joint Categorization and Segmentation
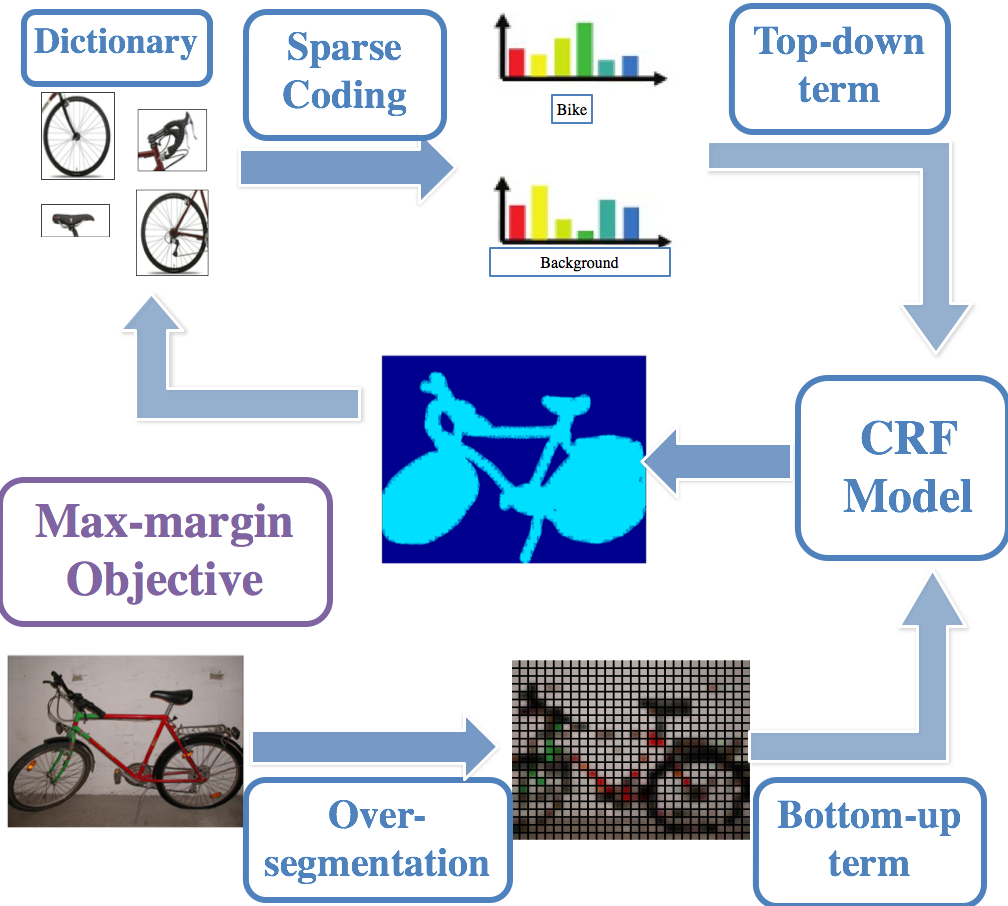 A popular trend in semantic segmentation is to use top-down object information to improve bottom-up segmentation. For instance, the classification scores of the Bag of Features (BoF) model for image classification have been used to build a top-down categorization cost in a Conditional Random Field (CRF) model for semantic segmentation. Recent work showed that discriminative sparse dictionary learning (DSDL) can improve upon the unsupervised K-means dictionary learning method used in the BoF model due to the ability of DSDL to capture discriminative features from different classes. However, to the best of our knowledge, DSDL has not been used for building a top-down categorization cost for semantic segmentation. In our work [2], we proposed a CRF model that incorporates a DSDL based top-down cost for semantic segmentation. We showed that the new CRF energy can be minimized using existing efficient discrete optimization techniques. Moreover, we proposed a new method for jointly learning the CRF parameters, object classifiers and the visual dictionary using a max-margin formulation. Our experiments demonstrated that by jointly learning these parameters, the feature representation becomes more discriminative and the segmentation performance improves with respect to that of state-of-the-art methods that use unsupervised K-means dictionary learning.
A popular trend in semantic segmentation is to use top-down object information to improve bottom-up segmentation. For instance, the classification scores of the Bag of Features (BoF) model for image classification have been used to build a top-down categorization cost in a Conditional Random Field (CRF) model for semantic segmentation. Recent work showed that discriminative sparse dictionary learning (DSDL) can improve upon the unsupervised K-means dictionary learning method used in the BoF model due to the ability of DSDL to capture discriminative features from different classes. However, to the best of our knowledge, DSDL has not been used for building a top-down categorization cost for semantic segmentation. In our work [2], we proposed a CRF model that incorporates a DSDL based top-down cost for semantic segmentation. We showed that the new CRF energy can be minimized using existing efficient discrete optimization techniques. Moreover, we proposed a new method for jointly learning the CRF parameters, object classifiers and the visual dictionary using a max-margin formulation. Our experiments demonstrated that by jointly learning these parameters, the feature representation becomes more discriminative and the segmentation performance improves with respect to that of state-of-the-art methods that use unsupervised K-means dictionary learning.
Hierarchical Joint Max-Margin Learning of Mid and Top Level Representations for Visual Recognition
Currently, Bag-of-Visual-Words (BoVW) and part-based methods are the most popular approaches for visual recognition. In both cases, a mid-level representation is built on top of low level image descriptors. In addition, top level classifiers use this mid-level representation to achieve visual recognition. While in current part-based approaches, mid and top level representations are usually jointly trained, this is not the usual case for BoVW schemes. A main reason for this is the complex data association problem related to the usual large dictionary size needed by BoVW approaches. As a further observation, typical solutions based on BoVW and part-based representations are usually limited to extension of binary classification schemes, a strategy that ignores relevant correlations among classes. To tackle this issue, we developed a novel hierarchical approach to visual recognition that jointly learns a mid-level dictionary of visual words and a top-level multiclass classifier. In terms of dictionary learning, we departed from the usual vector quantization or sparse coding schemes commonly used in BoVW models. Instead, we used linear SVMs to characterize each word with a max-pooling strategy. In terms of classifier learning, we used a max-margin learning framework where both mid- and top-level representations are learned jointly, thereby providing more discriminative visual words.
In our work [3], we used a max-margin structured-output learning framework with a soft-assignment of feature descriptions to dictionary atoms. We solved the optimization problem using an alternating minimization scheme. In our work [4], we adopted a latent structured-output learning framework with a hard assignment of feature descriptors to dictionary atoms. In our work [5], we departed from the frameworks used in [2] and [3], which used an l2-regularizer on the classifier weights. Instead, we used a group-sparse regularizer, which encourages choosing very few words to represent each class, and very few classes to utilize each visual word. We tested our proposed method on several popular benchmarks. Our results showed that, by jointly learning mid- and high-level representations, and fostering the sharing of discriminative visual words among target classes, we were able to achieve state-of-the-art recognition performance using far less visual words than previous approaches.
Acknowledgement
Work supported by grants ONR Young Investigator Award N00014-09-10839 and NSF 1218709.
Publications
[1]
Using Global Bag of Features Models in Random Fields for Joint Categorization and Segmentation of Objects.
[2]
Sparse Dictionaries for Semantic Segmentation.
[3]
Joint Dictionary and Classifier Learning for Categorization of Images Using a Max-margin Framework.
[4]
Hierarchical Joint Max-Margin Learning of Mid and Top Level Representations for Visual Recognition.
IEEE International Conference on Computer Vision, December 2013.
Download: [pdf]
Download: [pdf]
[5]
Learning Shared, Discriminative, and Compact Representations for Visual Recognition.
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence.
Download: [HTML]
Download: [HTML]